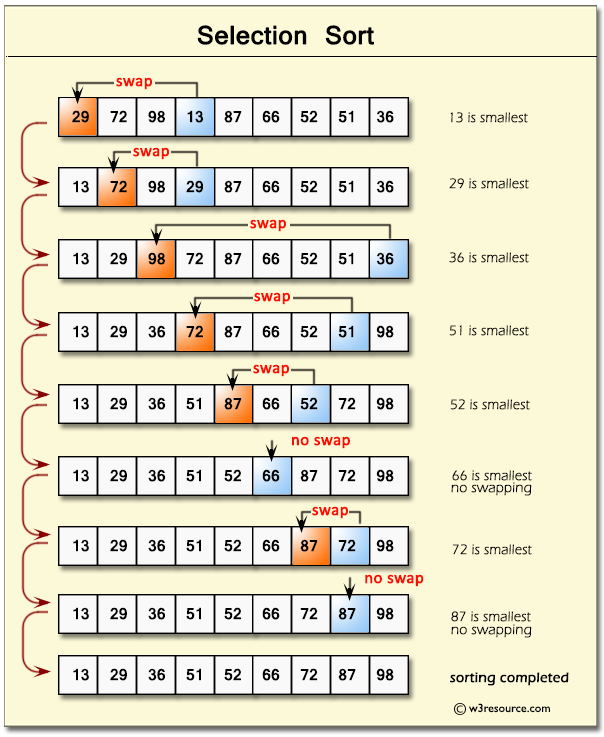
선택 정렬 : 맨 처음 인덱스부터 시작하여, 가장 작은 값을 찾아 앞쪽으로 정렬한다. (큰 값으로 할때는 반대)
for i_step in range(len(arr)):
min_step = i_step
for i in range(i_step+1, len(arr)):
if arr[i] < arr[min_step]:
min_step = i
arr[min_step], arr[i_step] = arr[i_step], arr[min_step]
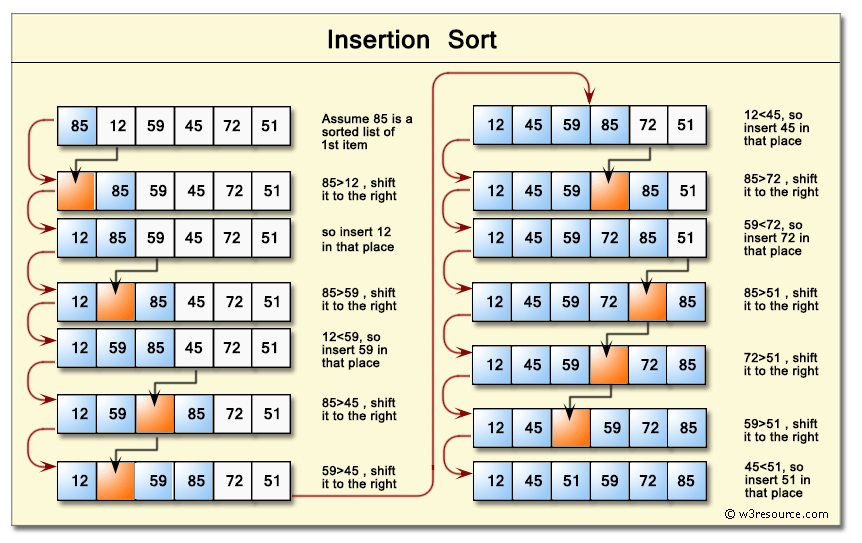
삽입 정렬 과정
삽입 정렬 : 두번째 인덱스부터 시작하여, 자신 앞쪽의 원소들과 비교해서 적절한 위치로 정렬한다.
arr = [9,5,1,4,3]
for step in range(1, len(arr)):
for i in range(step, 0 , -1):
if arr[i-1] > arr[i]:
arr[i-1], arr[i] = arr[i], arr[i-1]
버블 정렬 과정
버블 정렬 : 이웃하는 두개의 원소를 비교하며 정렬한다.
for step in range(len(arr)):
for i in range(0, len(arr)-step-1):
if arr[i] > arr[i+1] :
arr[i], arr[i+1] = arr[i+1], arr[i]
⚙️ Pandas
📌데이터 전처리
apply + lambda : 기준 축에 있는 모든 데이터를 대상으로 작업을 반복 수행한다.
from numpy import nan as NA
data = pd.DataFrame(
data = [
[1, 6.5, 3],
[1, NA, NA],
[NA,NA,NA],
[NA, 6.5,3]
]
)
data.dropna()
# data.dropna(axis=0, how="all", thresh=1)
# axis : 기준 축 설정
# how = "all" : 모든 값이 NA여야 제거
# thresh = n : n개 미만으로 정상적인 데이터가 있으면 제거
DataFrame.fillna() : NA값을 특정 값으로 채운다.
data.fillna({1:0, 2:9999} # 1번 칼럼은 0으로, 2번 칼럼은 9999로 채움
📌DataFrame의 기타 메서드
DataFrame.describe() : 칼럼들에 대한 기본적인 수치정보 제공(평균, 표준편차, 데이터수, 4분위수..)
DataFrame.corr() : 칼럼들의 상관관계 제공
DataFrame.info() : 칼럼들의 자료형 제공
DataFrame.index/columns.unique() : 중복값이 존재하는지 확인(초기 체크 핵심 요소)
📌파일 입출력
pd.read_csv(path) : 경로에 존재하는 csv 파일 정보를 가져온다.
import pandas as pd
path = "/content/02_surveys.csv"
data = pd.read_csv(path)
drive.mount() : 내 GoogleDrive를 Colab과 연동한다.
from google.colab import drive
drive.mount("/content/"원하는 폴더")
files.upload() : colab에 파일을 선택하여 업로드한다.
from google.colab import files
my_file = files.upload()
💡 GapFor 컬럼에 시가,종가,고가,저가 4개 값 중 최고값-최저값의 차이를 for를 사용해 날짜별로 계산해서 기록하기
stock_price_df["GapFor"] = 0
for i in range(len(stock_price_df)):
stock_price_df.iloc[i, 5] = max(stock_price_df.iloc[i, 0:4]) - min(stock_price_df.iloc[i, 0:4])